
6 mins to read

The unstoppable forces of cloud and agile development are driving momentous changes in how enterprises build, deploy, and run applications. All in all, the cloud has led to serious business growth. However, this growth has resulted in new and unique challenges and implications, among them is data sprawl. What is data sprawl? First, let’s explore what has led many organizations to experience sprawl.
Out with the Datacenter, in With the Cloud

Gartner assumes that by 2025, 80% of enterprises will have shut down their traditional data centers, and rightfully so as the number of enterprises adopting public cloud rises year over year. The global pandemic catered to this prediction, as more companies made efforts to shift to cloud-centric infrastructure and applications as a result of it. Adoption of the public cloud is only going up from here, but with the cloud comes a proliferation of cloud platforms, accounts, instances, identities and more.
The Cloud Brings Options
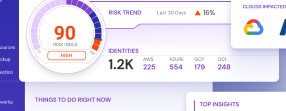
According to an Osterman Research Paper, 80% of the companies in the cloud have adopted a multi-cloud strategy using multiple cloud service providers (CSP) such as Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP) and Oracle to name the top contenders.
Datastore options are fruitful today too; to name just a few among the top providers, organizations have Amazon Secure Storage Service (S3), MongoDB, Elasticsearch, CouchDB, Cassandra, Dynamo DB, Azure Blobs, Azure Cosmos DB, and many, many more available to them. With all these options, it’s self-evident that many corporate infrastructures no longer have a physical or logical concept of a ‘data center.’ These options also enable a level of instantiation and decentralized management never before seen. DevOps professionals can stand up a new data store with no oversight, and are often managing data. This makes data in the cloud more elusive, intangible, and hard to keep track of, especially when you’re working across multiple clouds.
So What is Data Sprawl in the Cloud?
Data sprawl is the experience of hosting a proliferation of data in many different, constantly evolving, places across your cloud. The experience is often unmanageable and hard to keep track of. As we previously mentioned, there is a lot of variety in the cloud – you may have data across multiple platforms, in different data stores, and being accessed by many identities throughout the day. The sprawl doesn’t stop there, that’s just recognizing static data, but data is always moving in the cloud too. It may live in one place, but it’s often in transit across your environment for seconds at a time when it needs to be used, edited, or accessed. According to a study by CSC, only 33% of organizations are able to maintain a single view of their data across all clouds, and only 60% can securely share data between cloud providers.
Why is Data Sprawl Concerning?
Losing control of your data comes with several concerns. The first is not knowing where all your data is. This is a critical component, and often the first step, to a strong data security program in the cloud. Whether you think you know where your data is and you’re wrong, or you simply just don’t know, you’re unable to protect it. Oftentimes, you may think you know where your data is supposed to be, but it is elsewhere, or your data is in places it shouldn’t be (i.e. sensitive data from Production being moved to an entirely different region.) The most poignant consequence of your data being where it shouldn’t be is falling out of compliance with data or privacy regulations, meaning a hefty fine is coming your way among other auditing concerns.
Without knowing where your data is, you are unable to know what your data is. Data classification and tagging is the next step in better protecting your data. Knowing what your data is in terms of type and sensitivity, allows you to prioritize data protection based on how critical it is – not all data is the same.
Finally, after establishing where your data is and what it is, you can focus on the who or what is accessing it. The cloud sees a proliferation of identities in the average environment, and many of these are non-person identities, meaning roles, service accounts, instances, or connected devices. Yes, you need to not only know what your person identities are accessing, but also your machine identities. A lot of cloud operations depend on these non-person identities, with them accessing your data on a daily or even hourly basis. Often organizations are running completely blind to their non-person identities and what they can and are accessing. This is a major gap in your program, and a dangerous one.
Now that we’ve covered the where, what, and who/what of data in the cloud, it’s only fair to recognize the obvious ultimate concern of losing control of your data – cloud data breaches. A 2022 Thales Cloud Security Report found nearly half of the businesses they surveyed experienced a cloud data breach or failed an audit. So where do you go from here to ensure your future is different?
Managing Identity & Data in the Cloud
Data is the oil of the digital era, but in this era, the oil rigs are ephemeral and countless. Virtual Machines (AWS EC2, Azure and GCP VMs), containers, serverless functions, other non-person identities, admins, and dev teams are the countless fleeting rigs that drill into your data on a daily basis.

Because of this, identity and data should be at the center of your cloud security strategy. Permissions and access create a bi-directional channel between data and identity. From the data side looking outward, you want a clear picture of all the identities that can access it, how they are accessing it and what they are doing with it and from the identity side looking out, you need to see all the permissions an identity has for your data. Getting this level of visibility on your own is difficult, so cloud providers like AWS, Azure and GCP offer data and identity solutions, however these tools can fall short. The different platform tools are markedly different and only work for the platform they’re hosted in. This becomes an issue for the many enterprises working multi cloud.
The paths between identity and data are extremely complex and sometimes covert in the cloud. Access control lists, inline policies, group inline policies, role inline policies, assumed roles, switched roles federation, and managed policies all influence access to critical data. There needs to be a way for organizations to gain visibility and track data access and movement across multiple clouds, tons of cloud accounts, and thousands of data stores.
How to End Data Sprawl
Sonrai Security recommends approaching your data protection in four steps.
1. Discover your data
To protect your data you first need to find it across every platform, account, or resource. Continuous scanning not only looks for new data, but discovers when data appears in new places. A large part of the discovery process is doing a data inventory. You want a real-time picture of all the data in your environment.
2. Classify your data
Not all data is created equal, so you need to not only know where your data is, but also what it is. Data classification analytics are used to determine data type, importance, and risk to the business. This context is key in helping you prioritize what is most important. Data tagging looks like labeling your data store with a ‘name tag’ and then a ‘value tag’ for easy identification. An example may look like DataClassification:Confidential or DataType:CustomerPII. These tags allow you to know this is highly-sensitive content and should be prioritized in protecting.
3. Lock down your data
Leveraging a CIEM solution will help you lock down your sensitive data in a number of ways. First, it will help you inventory all identities, person or non-person, and reveal their effective permissions. This allows you to see what and who all your identities are, and also discover everything they can access and what they can do with that access. A CIEM tool allows you to enforce a least privilege policy across your environment, but that’s just half the battle – staying there is the other half.
Once you have visibility into your data and are at least privilege, you need to continuously audit your environment. Periodic or sporadic auditing doesn’t cut it when non-person identities are accessing your data for seconds at a time, at multiple moments a day. Auditing depends on first defining a secure baseline (least privilege) and then you can effectively monitor for deviations from that baseline. An example might be detecting that an Internet connected VM in Dev, that happens to have a vulnerability on it, that has never accessed a sensitive datastore in Prod before, suddenly has overnight.
4. Protect your data
Once you have a program in place allowing you to understand and detect security threats, the next step is actually protecting your data. A critical component of protecting your data is leveraging automation and organized workflows. The scale and speed of the cloud is unmanageable without automating the process of detecting concerns, and notifying the right team, at the right time, in an organized manner. Automation also comes into play for remediation efforts. Some security solutions include pre-set remediation and prevention bots to pick up where people left off.
Total Cloud Security
While you might have data security on the mind, data does not exist in isolation in the cloud. There are four major cloud pillars including data, identity, platform, and workloads and these pillars are deeply intertwined. Sonrai Dig offers solutions for each of these major pillars all in one integrated platform so you have the visibility and context needed to secure the cloud.
If you would like to learn more, consider exploring our Cloud Data Loss Prevention solution or the rest of our Cloud Security Platform.
