
8 mins to read
 2022
2022 Data is the most valuable commodity in your business, so why aren’t you treating it like it is important? Every business runs on data. Bad actors and hackers target companies large and small, across industries and countries to gain access to it. Hackers skill-up to find misconfigurations and vulnerabilities just to try and access your data. The costs are high, so the protection and planning in place to mitigate risk must be too. But you may be missing a critical first step to protecting your company’s data if you are not using data classification in your cloud.
As CISO, you’re tasked with protecting, storing, and managing more information than ever before. Keeping this abundance of data private, secure, and in compliance requires a higher level of data management, visibility, and control than ever before. You must manage a range of tools and practices. One of the leading privacy tools and practices is data classification.
Data governance ― locating, identifying, organizing, and maintaining data ― is critical to your company’s short and long-term success. There’s simply no other way to ensure that you can access it efficiently or protect it effectively unless you start with the basics. Our experts suggest starting with methodical and cloud-specific data classification.
Our experts suggest starting with methodical and cloud-specific data classification.
What is Data Classification?
Data classification is the process of separating and organizing data into relevant “classes” based on your organization’s characteristics. Data classification examples include sensitivity level, risk presence, and relevant compliance regulations. To protect sensitive data, you must have visibility into it. Then enterprises must handle each class of data in ways that ensure only authorized identities, users, and pieces of compute can gain access, and that the data is always handled in full compliance with all relevant internal and external regulations.
When done right, data classification makes using and protecting data easier and more efficient. Yet, it’s often overlooked in cloud strategies.
What is Data Tagging?
Data tagging falls under the umbrella of classification. It allows you to clearly label your data so that you know exactly what it is and where it is. This is often broken down into something like a ‘name’ tag and then a ‘value’ tag. For example: DataClassification:Confidential, DataType:CustomerPII, DataOwner:DevOpsTeam1. These tags allow you to better manage your data as well as identify a risk such as sensitive data that is found in a Dev environment.
It is no longer sufficient to just classify data as ‘sensitive’ or not, as there are gradations of data sensitivity. Additionally, there are different data formats, structures and storage. This is why custom classification is a must-have.
Why Classifying Your Data is Important
To “know your data” means having an understanding where all data is located across an enterprise. As CISO, you cannot effectively protect customer, employee, and corporate information if you don’t know the following:
- What data exists across our organization
- Where it resides exactly
- Its value and risk to the organization if it is compromised
- Compliance regulations and internal controls governing the data
- Who and what is allowed to access and use the data
Data classification provides a consistent process that identifies and tags all information wherever it resides across the organization. It works by enabling the creation of attributes for data that prescribe how to handle and secure each group according to corporate and regulatory requirements. Standards organizations, such as the International Standards Organization (ISO) and the National Institute of Standards and Technology (NIST), recommend data classification schemes so information can be effectively managed and secured according to its relative risk and criticality, advising against practices that treat all data equally.
So you should ask yourself these critical questions when it comes to classifying your data:
Ask Yourself “What is My Data?”
Understanding what your data is by class can help you prioritize data when there is a risk, threat, or attack on your most critical assets. You’ll want to place priority on specific data classes rather than treating all threats as if they are of equal risk.
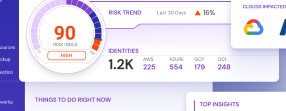
To determine which assets are business critical, you’ll need to discover sensitive data and more risk-presenting assets, like assets with broad permission access and secrets exposure. You’ll need to manage this process by automatically tagging and classifying critical assets themselves.
Common classifiers include PII, NIST, ISO, HIPAA, PCI, and GDPR. It sounds elementary, but no risk can be mitigated if it is not truly understood. So start simple, understand what your data is and classify it.
Ask Yourself “Where is My Data?”

You can’t protect what you can’t find, which is why it is so critical that you know where your data lives, whether it’s in your on-prem configurations, your cloud, and multi-cloud deployments, or on your far-flung remote devices. While the question, ‘where is my data?’ is simple, answering it is not always easy. A basic step in data security is first finding your data.
Discovery, as you know, is important. This process will be difficult to manually execute, as the ephemeral nature of the cloud makes keeping tabs on your data an ongoing challenge. This is why some organizations rely on cloud security tools that can automatically, visualize and map identity and data across your clouds. Tools, like Sonrai, can help classify data by leveraging machine learning to determine data type, importance, and risk to help detect and protect data classes.
Chances are, your organization is suffering from cloud data sprawl. You may store some of your data locally and the rest on one or more cloud storage platforms. Data sprawl can be a serious issue, particularly when it comes to sensitive data, because you can’t protect what you cannot find.
Verify the security of your most important data with the right tooling. You’ll want to be able to scan your entire cloud, or multiple clouds, to discover sensitive data that is not properly protected or has been compromised. If you are using the right tools, unreported data assets will be found, identified and monitored across cloud accounts and developer teams. If a risk is identified, you’ll need to immediately prioritize the identified risks based on context and severity.
Ask Yourself “Who or What is Accessing My Data?”
You have people accessing data, but you also have non-person identities that may have access to your most sensitive data. AWS roles, Azure service principles, serverless functions and more are accessing your crown-jewel data.
When you have numerous developers running around in an environment, creating different roles and functions, chances are they will accumulate permissions across multiple groups, roles, services, and accounts.
The only way to close blindspot gaps and proactively manage identity and data security risks is to prioritize and conduct identity access reviews. By doing so, you can protect your data using the Least Access policy, and enforce the Principle of Least Privilege, ensuring only authorized identities access your data.
Ask Yourself “How am I Protecting My Data?”
Implementing controls around who and what has access to data is fundamental to any data security program. Although each unique cloud provider delivers services to manage access to data for their stack, they are not standardized across all the stacks available (e.g., AWS, Google, and Microsoft Azure), do not address third-party data stores, and often require use of low-level tools and APIs. To resolve this problem, data needs to be normalized in views and controls.
Because the data is easy to find, organizations can apply protections that lower data exposure risks, reduce the data footprint, eliminate data protection redundancies, and focus security resources on the right actions. In this way, classification both streamlines and strengthens organizations’ security programs.
Data is Scattered Everywhere: Prepare for the Worst
Massive volumes of data are stored, processed, and in transit across numerous organizations. This can pose significant challenges for enterprises that are responsible for managing and securing sensitive data. The ever increasing need to share information within and outside of your organization means it is even harder to control. This means your data may be scattered everywhere throughout your cloud. With lack of visibility and control, how are you preparing for when disaster strikes?
It is common for an organization to have at least some documentation on data classification standards, including access tiers, naming conventions, and so forth. But one critical effort to make sure you include is sufficient emphasis on the disastrous ramifications of exposure and what could result if that data ends up in the wrong hands.
It’s important to remember that your blast radius is usually much larger and more significant in the cloud. If someone compromises an account with admin privileges or a root account, for example, they could easily cascade across an entire data center and cause catastrophic damage to the business.
While cloud providers often advertise strong security and compliance measures, security is almost always a shared responsibility. Unfortunately, many companies rush into cloud migrations and recklessly spin up servers, assuming that providers like AWS will manage and fortify their accounts. As a result, these companies are often exposed to a variety of threats.
Ideally, companies should plan ahead to limit the amount of damage that a bad actor could cause. As Murphy’s Law goes, anything that can go wrong will go wrong; it’s only a matter of time. That being a case, you should anticipate that your cloud environments will be compromised eventually. Don’t wait until after you detect a breach to spring into action. By proactively reducing your attack surface, you can limit the impact.
Rewrite your data security policy based on the current location and impact of your data today. Establish clear guidelines that consider what would happen if this data was stolen or improperly exposed, and create a viable maintenance plan – you’ll be happy when you need it.
The Real Cost of Compromised Data
Data breaches and the resulting negative press can irreparably tarnish a company’s reputation. Reputation is a hard entity to measure, but a Forbes Insight report found that 46% of organizations who experienced a data breach also experienced reputational damage. Past reputational costs are obviously financial costs – the IBM Cost of a Data Breach Report found the average breach to cost an organization $4.24M.
Sometimes the cost is not just towards rebuilding or remediating after a breach, but actually hefty fines paid towards laws like GDPR (General Data Protection Regulation.) To put a number on it, the largest fine paid to date was $887M.
Your company could be fined today or even years from now. That’s why it is extremely important to keep up with two practices:
- Updating your data security documentation regularly to reflect new and updated regulatory controls and requirements
- And monitoring your data continuously. Checking every 90 days is no longer a valid methodology. You must audit your data continuously to remain compliant.
There’s No Silver Bullet… or is There?
Each of the cloud providers ― Google, Azure, AWS ― has tools that can help you implement new or modified categories and security levels to your data. Because of data and cloud sprawl, this means that you’ll have to manage your data across multiple clouds using multiple tools.
Similarly, if you change from one cloud provider to another, many of your lessons learned, controls, and processes won’t be applicable.
Also, as tempting as it may seem, you can’t take data from one cloud storage account and run an analytic to mix it with similar data from another cloud storage account. The data from both accounts may have been labeled as sensitive, for example, but the output is likely to be a combination of different tiers – remember, there are gradations of sensitivity.
These challenges are why many businesses seek out third-party cloud security platforms to centralize their data security and reduce tool stacking. Sonrai Security has a data classification engine that works across all cloud providers. You can also use its out-of-the-box classifiers and rebuilt configurations to recognize PII, credit card numbers, and more, or build your own custom classifiers.
While you’re at it, remain compliant with any industry standards with a continuous cloud footprint through Sonrai’s continuous monitoring and activity logs.
Remember, if you don’t know exactly where your data is, what it is, how impactful it is to the business, and who can potentially access it, you cannot sufficiently protect it.
If you’re interested in more education and strategy around data classification, watch our webinar: Data Classification Program for AWS and Azure: Deep Dive.
